Understanding LLMs: From Tokenization to Vocabulary
 Have you ever talked to ChatGPT or another AI and thought, "Wow, how does this thing actually understand me?" You’re not alone. These models are powered by something called transformers — a super smart piece of technology that changed the AI world.
Have you ever talked to ChatGPT or another AI and thought, "Wow, how does this thing actually understand me?" You’re not alone. These models are powered by something called transformers — a super smart piece of technology that changed the AI world.
In this blog, we’ll walk you through the process of how a transformer-based Large Language Model (LLM) like ChatGPT takes your input, processes it, and generates human-like responses. We’ll keep things simple and relatable so it all makes sense.
Note: This blog is an outcome of my understanding on LLM, if you find any mistakes please let me know in the comments. Your feedback will be much appreciated.
1. Tokenization: Breaking Down Text
The first step is tokenization — breaking your sentence into smaller parts called tokens.
These tokens can be:
- Words (like “apple”)
- Sub-words (like “appl” and “e”)
- Characters (like “a”, “p”, “p”, “l”, “e”)
Why? Because computers can’t understand raw text — they need smaller, consistent pieces to process.
Tool to explore: OpenAI Tokenizer
2. Vector Embedding: Turning Tokens into Numbers
Once the sentence is tokenized, each token is converted into a vector — a list of numbers that captures its meaning.
Instead of storing the word “apple” as just text, we turn it into numbers that capture its meaning.
Example:
- “apple” →
[0.12, 0.95, -0.45, ...] - “banana” →
[0.10, 0.98, -0.40, ...]
These vectors help the model understand that both words are fruits and kind of similar.
3. Positional Encoding
Words like “The dog bit the man” vs. “The man bit the dog” have the same words, but different meaning because of word order.
Transformers (the tech behind AI) need to know where each word is in the sentence. That’s where positional encoding comes in — it gives each word a tag that says “I’m the first word”, “I’m the second word”, etc.
4. Semantic Meaning (Context Matters)
Words can have multiple meanings depending on context: “He gave a pitch.” (Could mean a business idea or a baseball throw.)
Transformers look at surrounding words to figure out the correct meaning.
Example:
Sentence: “The startup founder gave a pitch.” Here, “pitch” means a business presentation.
5. Self-Attention (Spotlight on Important Words)
Transformers use self-attention to focus on related words in a sentence to understand their meaning better.
Example: Two sentences with “bank”:
- “She sat near the river bank.” (Bank = river shore)
- “He went to the bank to deposit money.” (Bank = financial institution)
Self-attention helps the model figure out which “bank” is meant by focusing on nearby words like “river” or “deposit.”
6. Softmax (Deciding What’s Important)
After figuring out which words are important, Transformers use softmax to assign probabilities to them.
Example: Sentence: “She sat near the river bank.”
Probabilities:
- “river” → 40% importance
- “bank” → 30% importance
This helps decide where to focus attention.
7. Multi-Head Attention (Multiple Spotlights)
Instead of one spotlight, Transformers use many spotlights at once to look at different aspects of a sentence — grammar, meaning, relationships between words, etc.
Example: In “The dog chased the ball,” one spotlight might focus on grammar (“dog chased”), while another focuses on meaning (“dog and ball”).
8. Temperature (Creativity in Responses)
When generating text, temperature controls how predictable or creative the output is.
Example: Input: “Once upon a time,”
- Low temperature (safe): “there lived a kind king.”
- High temperature (creative): “a flying toaster ruled the clouds.”
You can experiment it here: Google AI Studio
9. Vocabulary Size (How Many Words It Knows)
Vocabulary size refers to the number of unique tokens (words, subwords, or characters) a model can understand. These tokens are the building blocks for how the model processes and generates text.
Simple Example: Vocabulary Size in Action
Imagine two AI models with different vocabulary sizes:
- Model A: Vocabulary size = 10,000 tokens
- Model B: Vocabulary size = 50,000 tokens
Now, let’s see how these models handle the sentence:
“The astronaut explored the exoplanet.”
What Happens with Model A (10,000 Tokens)?
Model A has a smaller vocabulary, so it might not recognize rare or specialized words like “exoplanet”.
Instead, it breaks “exoplanet” into smaller subwords or tokens:
“exo” + “planet”
While it can still understand the general meaning (something related to planets), it loses the precise context of "exoplanet" being a planet outside our solar system.
What Happens with Model B (50,000 Tokens)?
Model B has a larger vocabulary and recognizes “exoplanet” as a single token.
Because it knows this word, it can understand the sentence more accurately and generate better responses related to space exploration.
The above article gives a high level overview of how LLM’s work. It doesn’t go deeper in technical aspects.
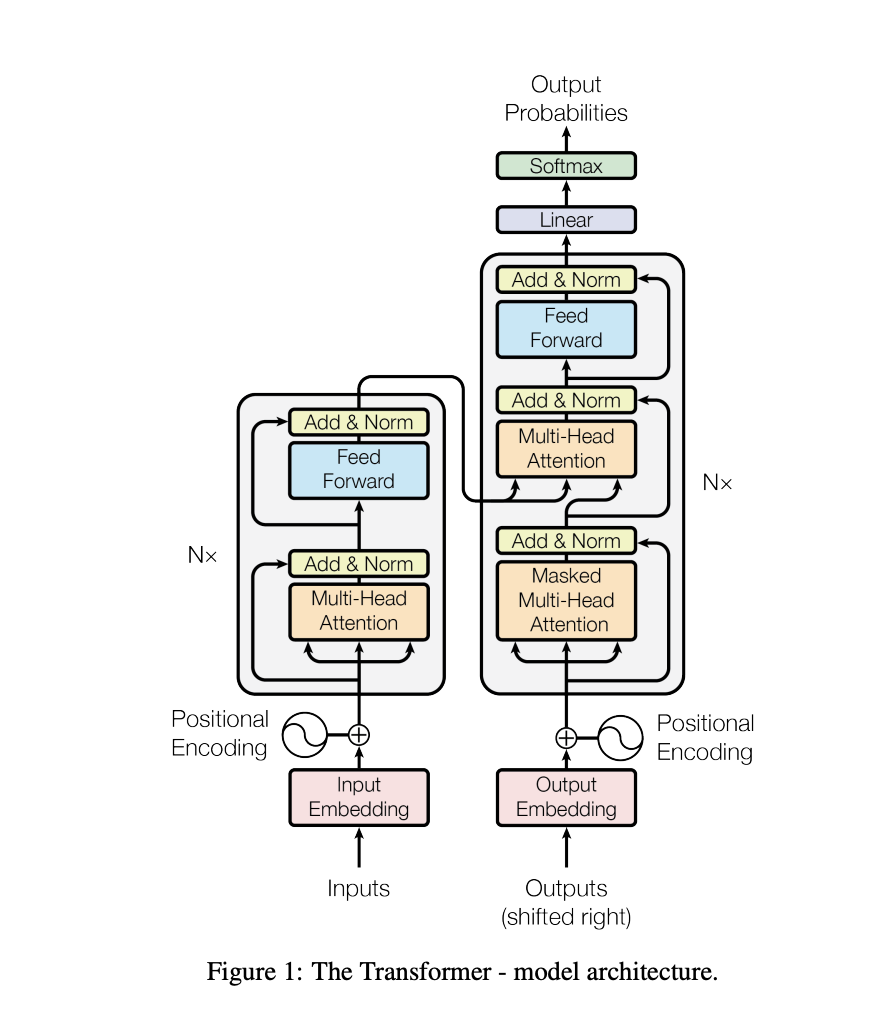 To learn more about the transformer (tech behind AI), please refer to the paper below.
Attention Is All You Need
Original Blog Post
To learn more about the transformer (tech behind AI), please refer to the paper below.
Attention Is All You Need
Original Blog Post
Found something incorrect?
If you spot any errors, outdated information, or have suggestions to improve this article, I'd love to hear from you. Feel free to reach out through any of the channels below.
Looking for a developer?
I'm a freelance web developer based in Hyderabad specializing in React & Next.js. If you need help with web application development or building a high-converting landing page, I'd love to chat.